Stream Processing Backpressure Smackdown
30 September 2019 - Comments… featuring Apache Storm, Apache Spark and Apache Flink.
In this series, we are going to put the top stream processing engines through their paces, and make them beg for mercy at the hands of a backpressure assault course.
Why the smackdown?
A few months ago a ‘thought-leader’ in the industry made a fairly blanket statement during Q&A at the end of a conference talk. It went something along the lines of:
Storm is a first-generation streaming engine, it’s been superceded by 2nd generation engines like Spark and Flink, and you should not consider it for new projects.
I was like:
Say whaaat?!!
It just really annoyed me, as I have production experience with both Storm and Spark, so I know that even today there are capabilities Storm has that Spark does not. For me, it is frustrating to hear such blanket statements from people who are so experienced. These sort of statements feed the fad-driven technology selection in our industry.
Rather than just take to Twitter to rage about it, I thought I would attempt some constructive input in this space, and do some comparisons between the most popular stream processing platforms; contributing some data rather than rhetoric.
This is how the backpressure smackdown came to be.
The contenders
The three contenders in our smackdown are going to be: Storm, Spark and Flink.
So what about X? Why wasn’t it included? There are a few notable omissions, driven by the following reasoning:
- I only wanted to include stream processing engines/platforms, and not libraries, which excludes Kafka Streams. The reason being that I wanted an apples and apples comparison. Plus, I think it is easy to underestimate the value of the additional features of these platforms and the effort required to replicate them.
- Other possible candidates like Samza and Heron seem to have limited use outside of the companies that created them - although this is a hard thing to quantify and is up for debate.
That said, if I get more time I might do a round #2 at some point, and cast the net a little wider. Who knows.
The caveats
- This is not a benchmark - we are not looking to compare raw speed between the engines.
- This is was performed on my laptop1 - so not distributed and missing certain factors like network I/O, etc. However, I think we will see that we are still able to exercise the engines sufficiently.
All the code will be available on Github, so you will be able to run these yourself and see if your results tally with mine.
Backpressure - what is it?
Simply put - backpressure occurs when a downstream processing task signals to some upstream component that it cannot keep up with the rate of flow, and should not be sent anymore data for the time being. The key characteristic we want to see in data-parallel streaming processing systems is that they minimize the impact of straggling components and maintain optimal throughput.
For instance, given a simple data-parallel streaming flow like that shown in Figure 1 …
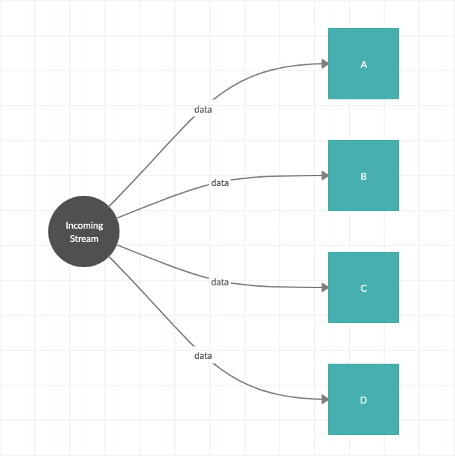
… where a single component might process data more slowly, and cause ‘straggler’ tasks within the dataflow graph, as shown in Figure 2. We want the processing engine to ensure the flow to other nodes is not unnecessarily impacted2.
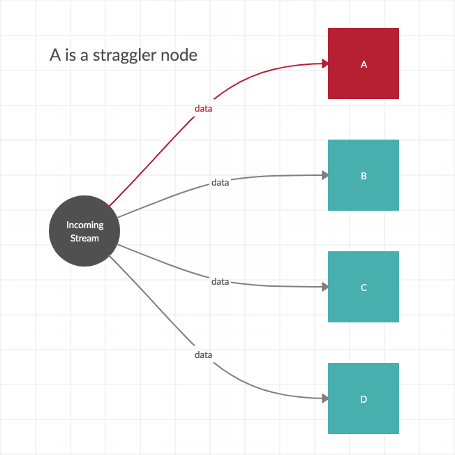
The worst case scenario is when other downstream tasks are impacted by the parallel straggler, and the streaming throughput is significantly reduced, as shown below in Figure 3.
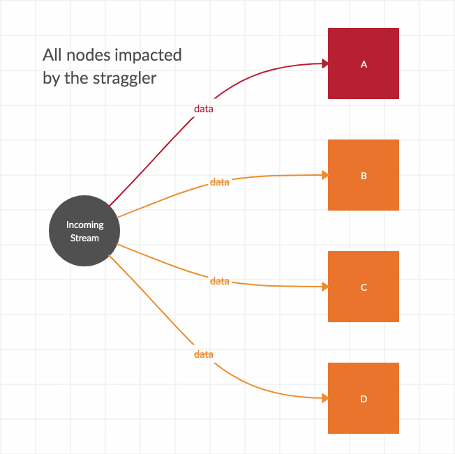
Backpressure - why might you care?
Well, you might not. However, there are a few production scenarios where this can have a massive impact:
- (multi-tenanant) Hadoop3 - where we have limited control over the load co-located with our jobs stream processing nodes, and where straggling nodes are an everyday occurrence. This holds for any multi-tenant environment, e.g. a Spark cluster deployed on AWS.
- data variance - less common, but there are scenarios where the data varies significantly itself and contains outliers requiring much more computation power to process.
The impact of misconfiguration or poor backpressure handling in these scenarios can be considerable. As we will see as we put the streaming engines through their paces, we can lose a significant amount of processing power on the majority of our processing nodes. In short, our streaming jobs can be reduced to a crawl.
Stream. Processing. Engine. Smack. Down.
As part of the smackdown we will be putting our contenders through four scenarios which will get progressively harder. To achieve this we will artificially generate a straggler in our dataflow scenarios:
- minimal variance - this is our baseline scenario, our happy path.
- slight straggler - our dataflow will contain a mildly straggling task.
- bad straggler - the straggling task gets worse and more frequent.
- constant straggler - a constant straggler, every streaming engines worst nightmare: one of our parallel tasks is going to be constantly slower than all the other tasks.
In this series we will put Storm, Spark and Flink through our backpressure assault course and then at the end regroup and round-up comparing their relative performance.
It’s going to be fun … unless you’re a stream processing engine : )
-
Given a budget and additional time, it would have been great to perform these runs in the public cloud on a distributed cluster. But back in the real world … want to sponsor me? ; ) ↩
-
Note, there are dataflows, such as consistent data partitioning, where a single downstream straggler can stop dataflow across all downstream nodes. In some of these scenarios there is little the stream processing engine can do for you : / ↩
-
Still pervasive despite the recent host of Hadoop is dead articles. ↩
Tags: Performance Storm Spark Flink Smackdown Data-Engineering
comments powered by Disqus