Apache Spark and the Backpressure Smackdown
02 October 2019 - CommentsThe next contender into the cage for the Streaming Backpressure Smackdown is Apache Spark 2.4.3. The first of our second-generation stream processing engines, can it crush our backpressure assault course as easily as Storm?
Enter Spark
Apache Spark is a unified analytics engine for large-scale data processing, as described on the website. To achieve this unification of both batch and streaming, Spark approximates streaming by reimagining it as a continuous series of small batch jobs.
This micro-batching model, originally described in the DStreams paper1, has a couple of implications:
- latency - this model cannot achieve the same low-level latency that true stream processing engines, such as Storm and Flink, can achieve.
- sensitivity to variance - as we will see, the micro-batching model is particularly sensitive to processing variance and straggling nodes.
A tale of two APIs
As it stands today, Spark has two separate APIs that can be used for stream processing:
- DStreams - the original Spark streaming API, which is stream-specific.
- Structured Streaming - the latest API, which unifies the Spark APIs for both stream and batch processing.
In addition to this, since Spark 2.3 the Continuous Processing mode can be used within the Structured Streaming API. This seeks to provide low-latency continuous stream processing, like both Storm and Flink. Note however that, Continuous Processing is still marked as experimental and as such supports a reduced feature-set when compared with Storm and Spark.
For the sake of completeness, during the smackdown Spark will run the gauntlet three times to cover DStreams, Structured Streaming and Continuous Processing.
Spark UI - the good, the bad and the disappointing
By comparison with the Storm UI, the Spark UI is definitely more aesthetically pleasing. More importantly, when used with DStreams, the UI provides a great visualisation of throughput over time, as shown below.
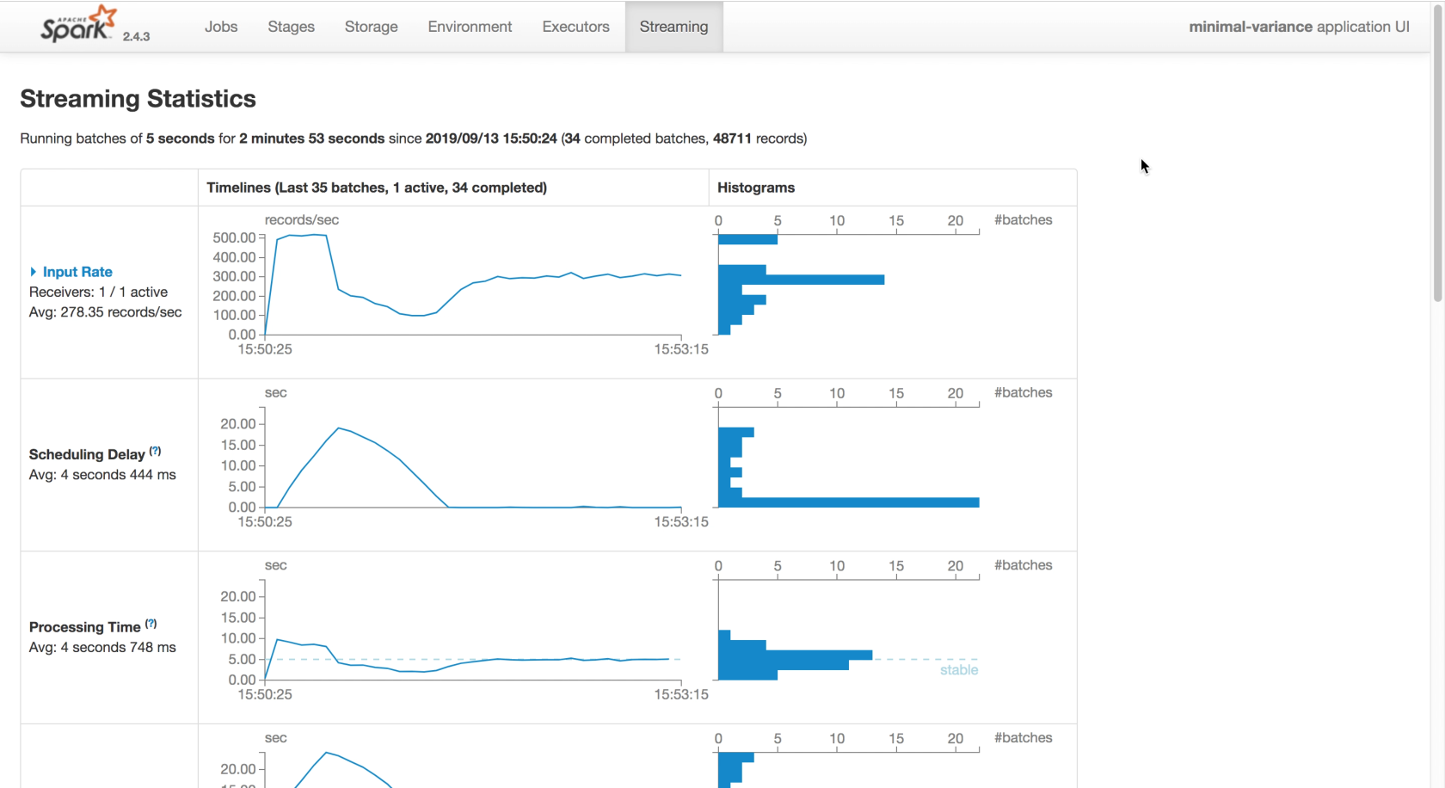
And whilst not the easiest UI to navigate, it also provides a great breakdown of the processing times within individual micro-batches, which we will make use of later for diagnostic purposes.
However, when we switch over to the Structured Streaming API …
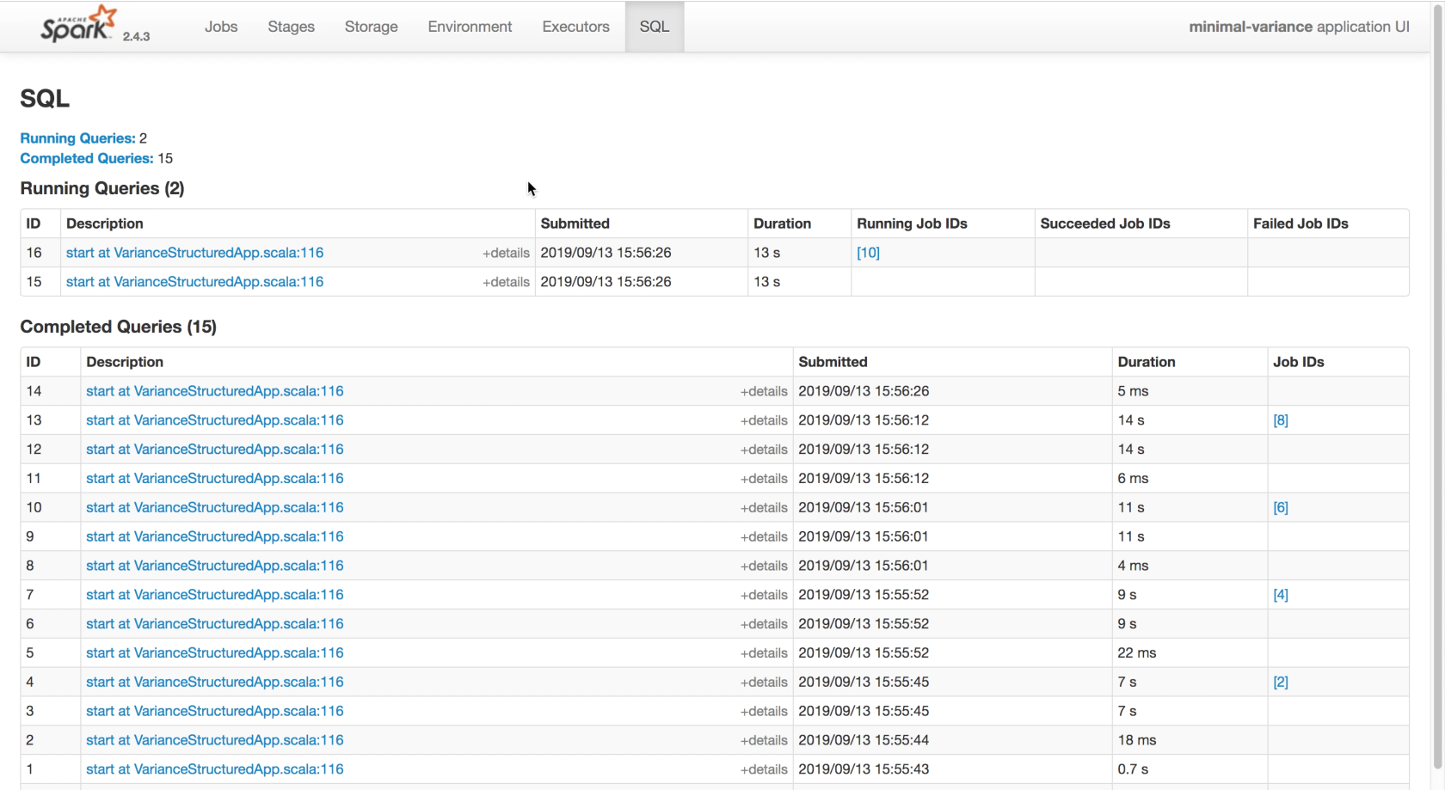
Whaaaat? Where did all those useful charts go? So for some reason, when using the newer Structured Streaming API you lose those awesome throughput visualisations. I presume this is due to some technical limitation. To me, this seems like a horrible regression from a monitoring and operational perspective : /
Fortunately, as with Storm, we are able to push our metrics out to a third-party system2. We will use Elasticsearch for this purpose, as we did for Storm.
Minor stumble
First, let’s run our easiest and hardest scenarios with a single data partition per core, a common noobie mistake.
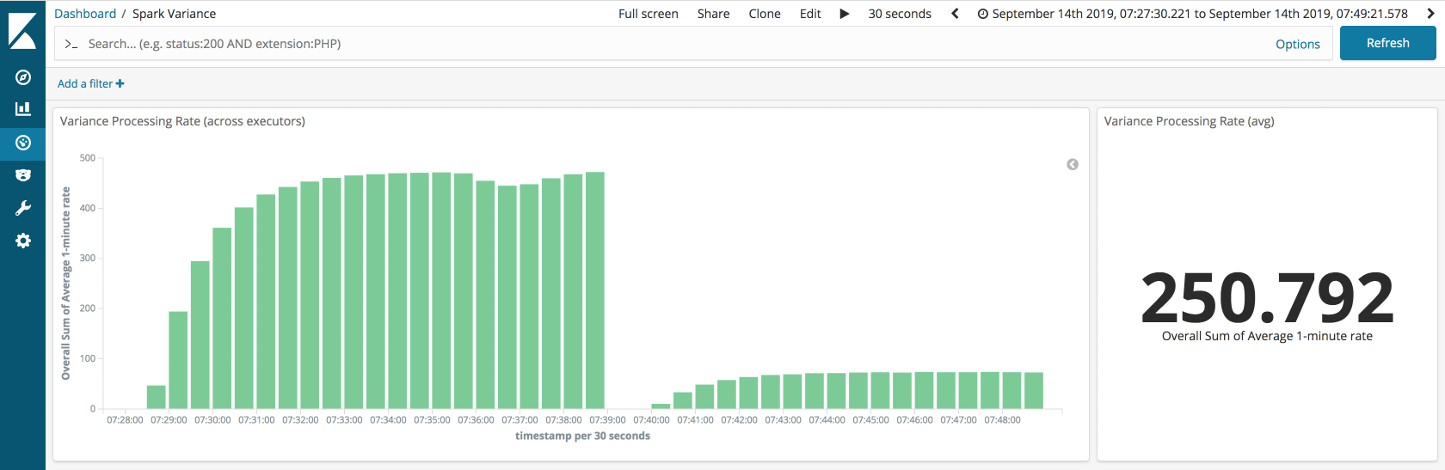
Hmm, this doesn’t look so good.
We have lost ~90% throughput. What is going on here?
Well, if we dig down into an individual micro-batch we can see why the constant straggler scenario is decimating our throughput.
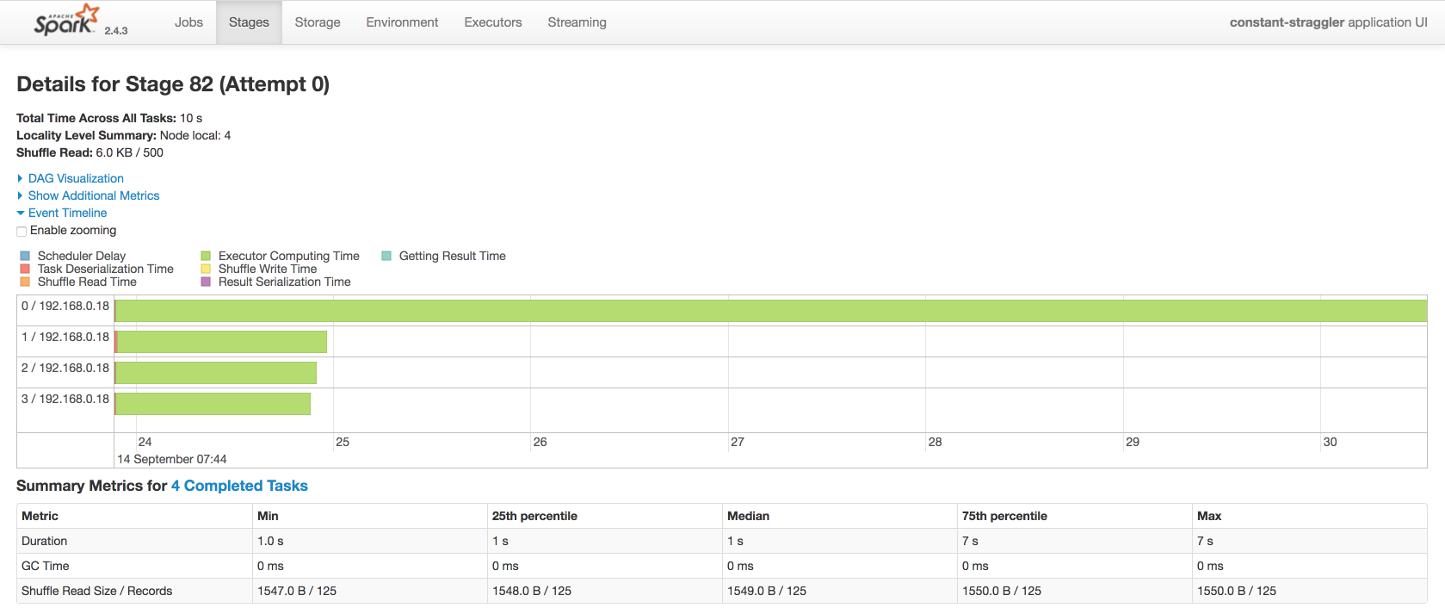
We can clearly see that three of our available cores are spending the majority of their time waiting for the straggling task to complete. Doh. This is a limitation of the micro-batch model. The next micro-batch cannot start until this micro-batch completes.
So Spark is rubbish, let’s throw in the towel, right? Well, no. Spark has a few tricks up its sleeve. Most notably, we can over-partition our data; creating more data partitions than cores. Spark is then free to assign outstanding partitions from our straggling node to other nodes, as shown below.
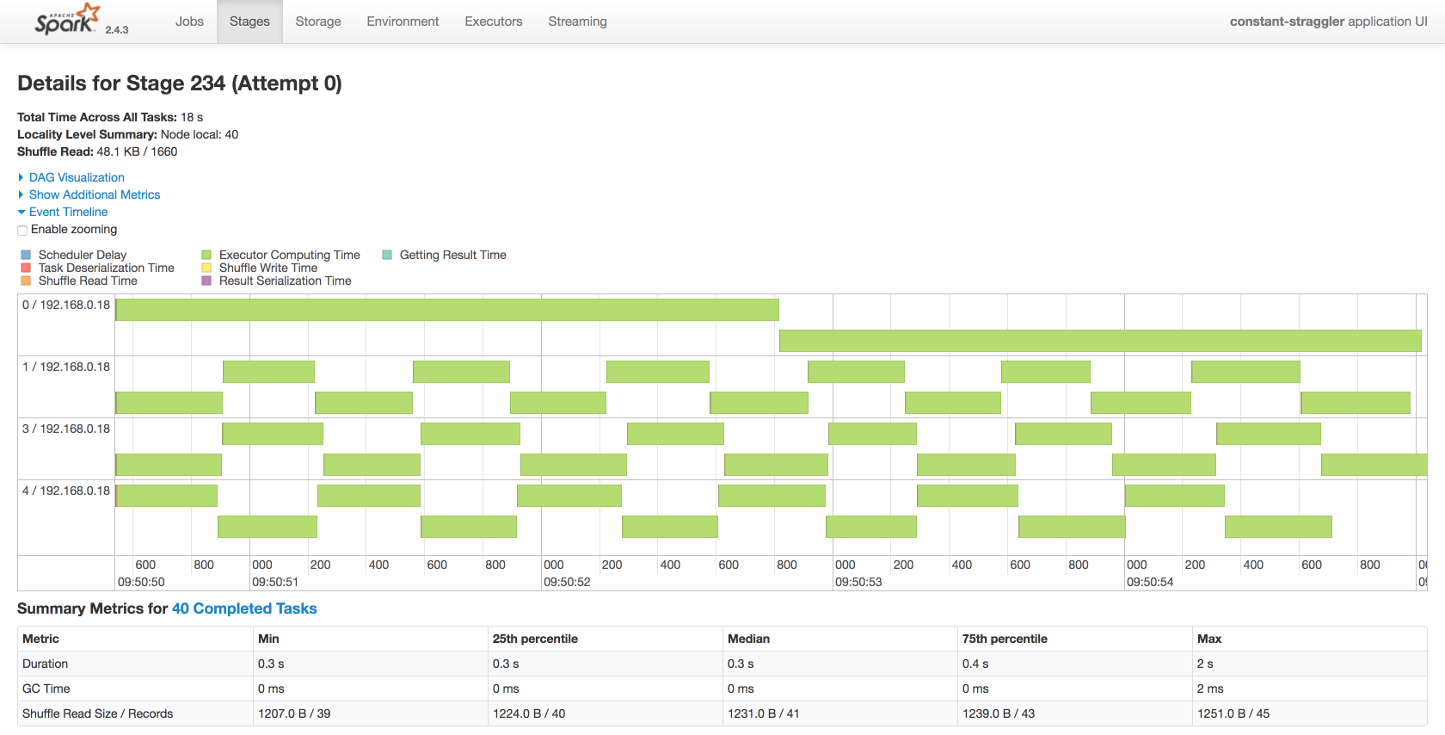
This is both simple and effective. As can be seen in this case, the non-straggling cores are now busy most of the time and the impact of the straggler has been minimized.
We will use this technique during our runs3.
Smack. Down.
Let’s get this on. How did Spark cope with our assault course of backpressure scenarios?4
DStream results
Ahem, so one slight issue was a loss of throughput due to the over-partitioning required to cope with the straggler scenarios. Below, you can see the first run of the minimal variance scenario, and then on the right the second run with over-partitioning in play5.
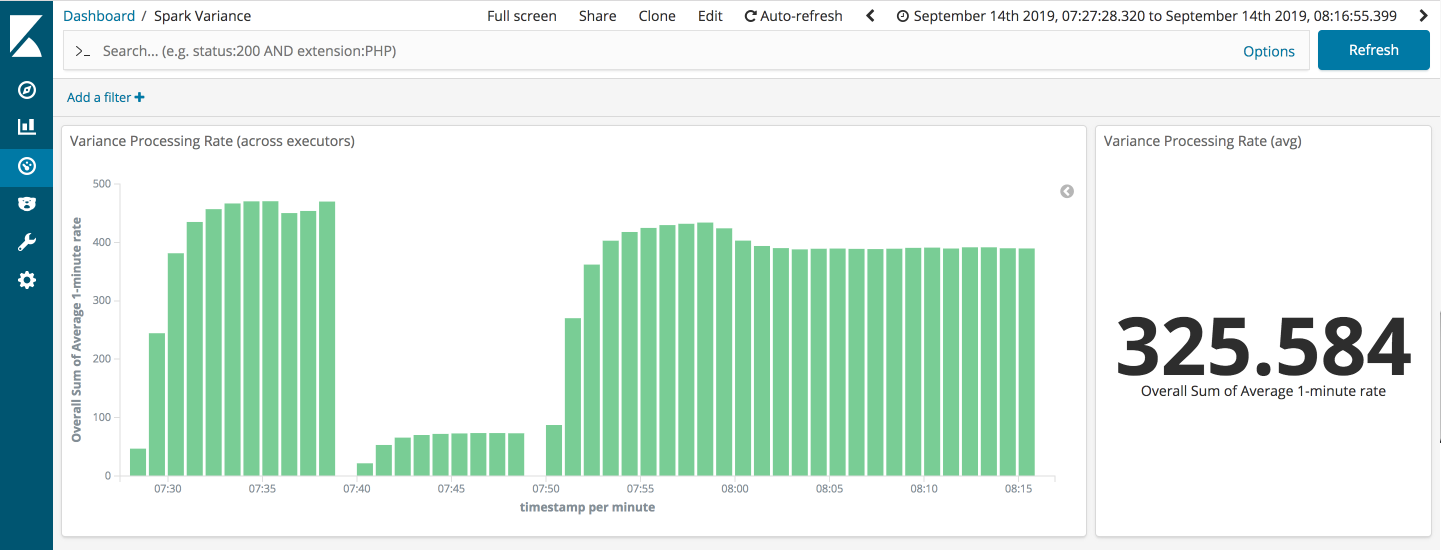
There is a clear performance penalty to the over-partitioning with the DStreams API. I measured it at > 15% which is a chunk to lose off of your top-end speed.
However, ignoring that for the time being, you can see that the DStream job holds up pretty well.
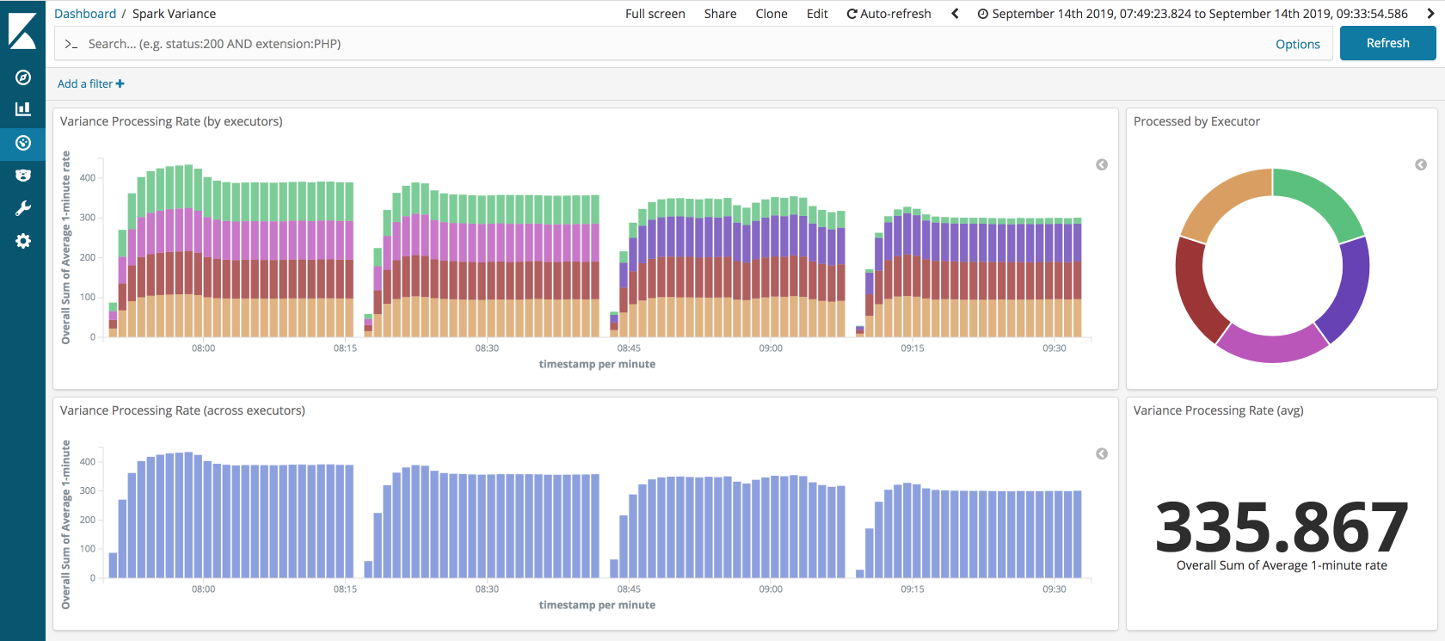
Let’s filter out the straggler executor, shown in green. We can clearly see there is no noticeable loss of throughput on the non-straggler executors.
Structured Streaming results
First things first, as can be seen from the first two runs below, Structured Streaming is not impacted in the same way that DStreams was when over-partitioning is applied to the minimal variance scenario.
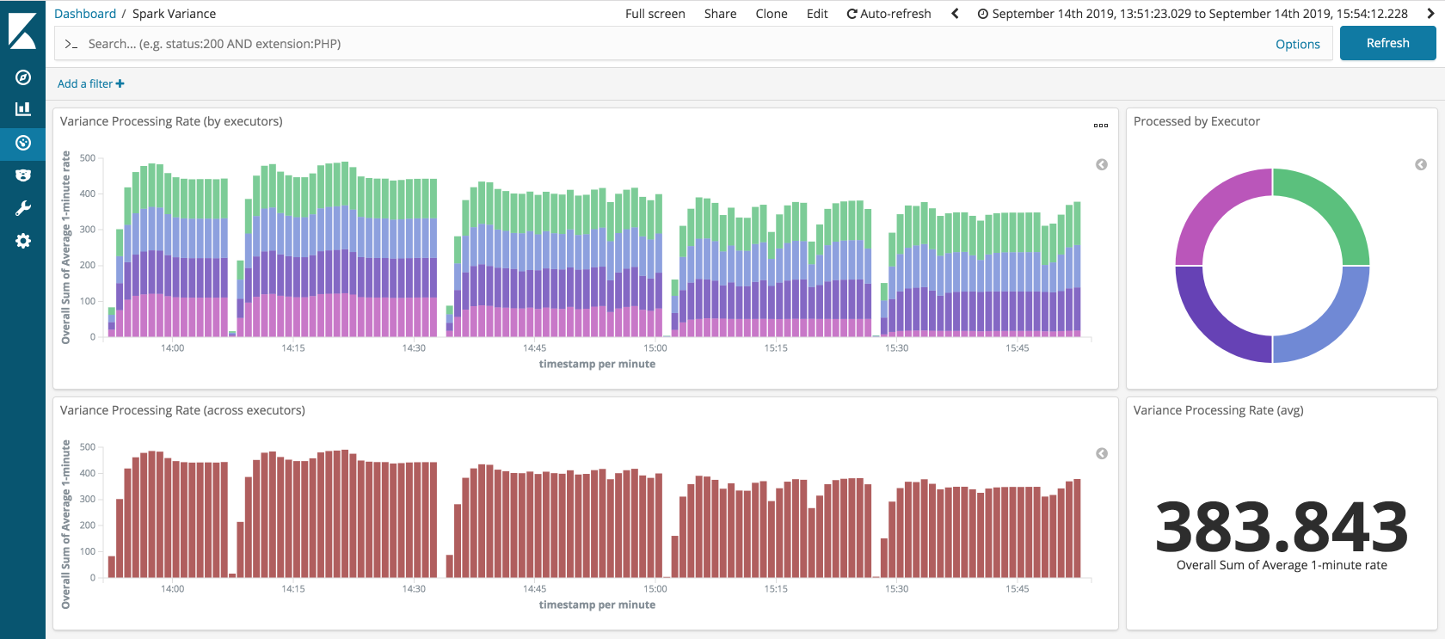
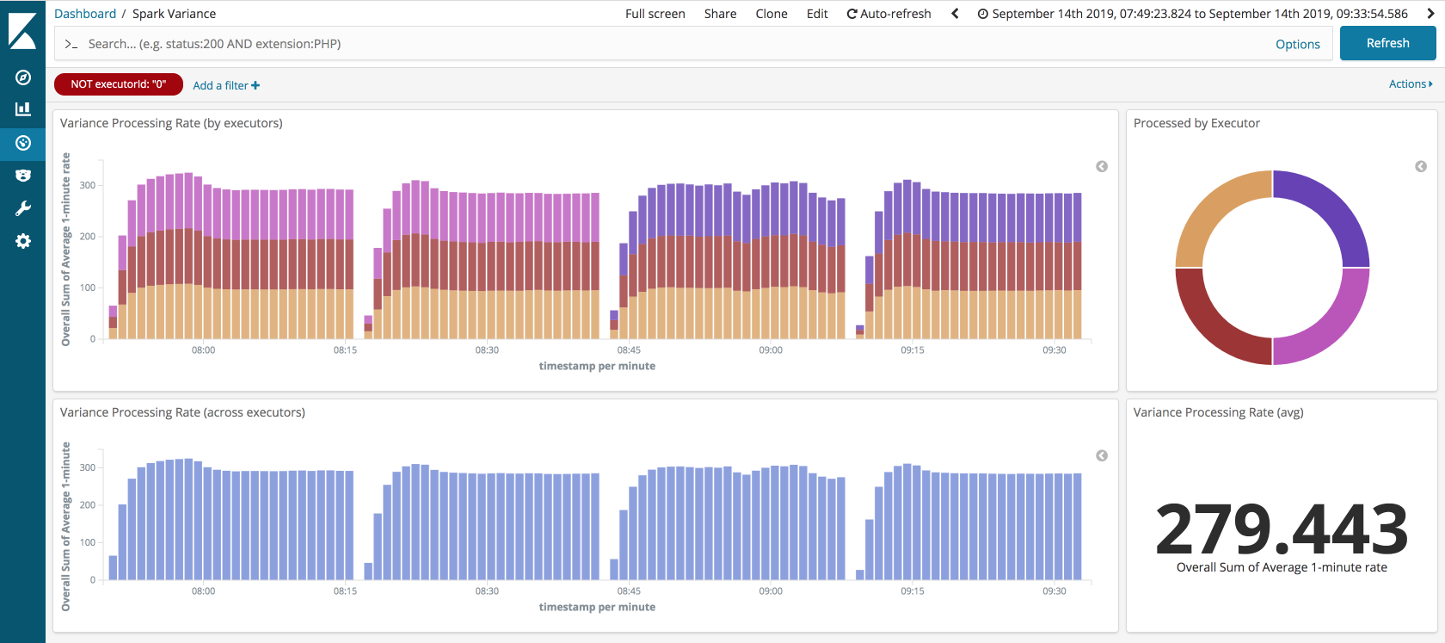
Looking at the remaining runs: top-end throughput was higher, if a little more variable, than with DStreams. Again, if we filter out the straggler executor (pink from above) then we can see the throughput through the non-stragglers holds up well.
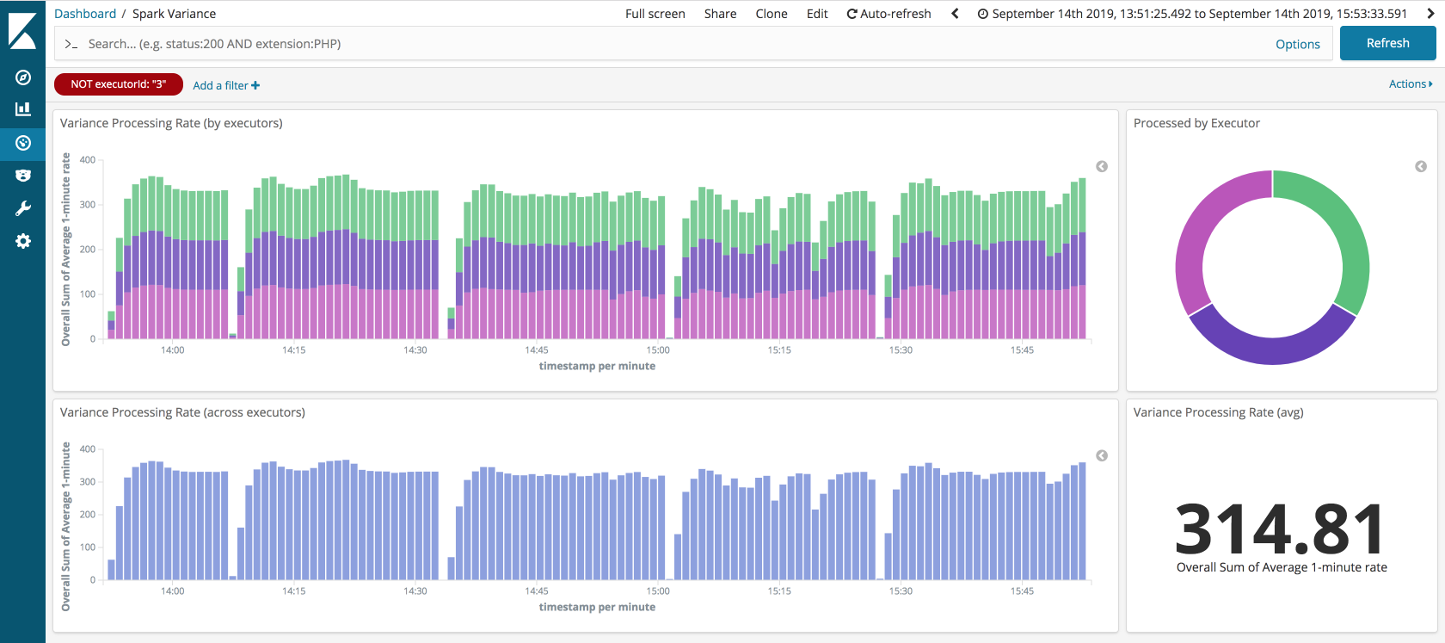
All in all, the Structured Streaming job has aced our backpressure assault course.
Continuous Processing results
So how about Spark’s new low latency API, can it deliver? Well, yes and no. It is worth recalling that this is a true streaming API. As a result, we can forget about any complications with the micro-batches; they are no longer in the picture.
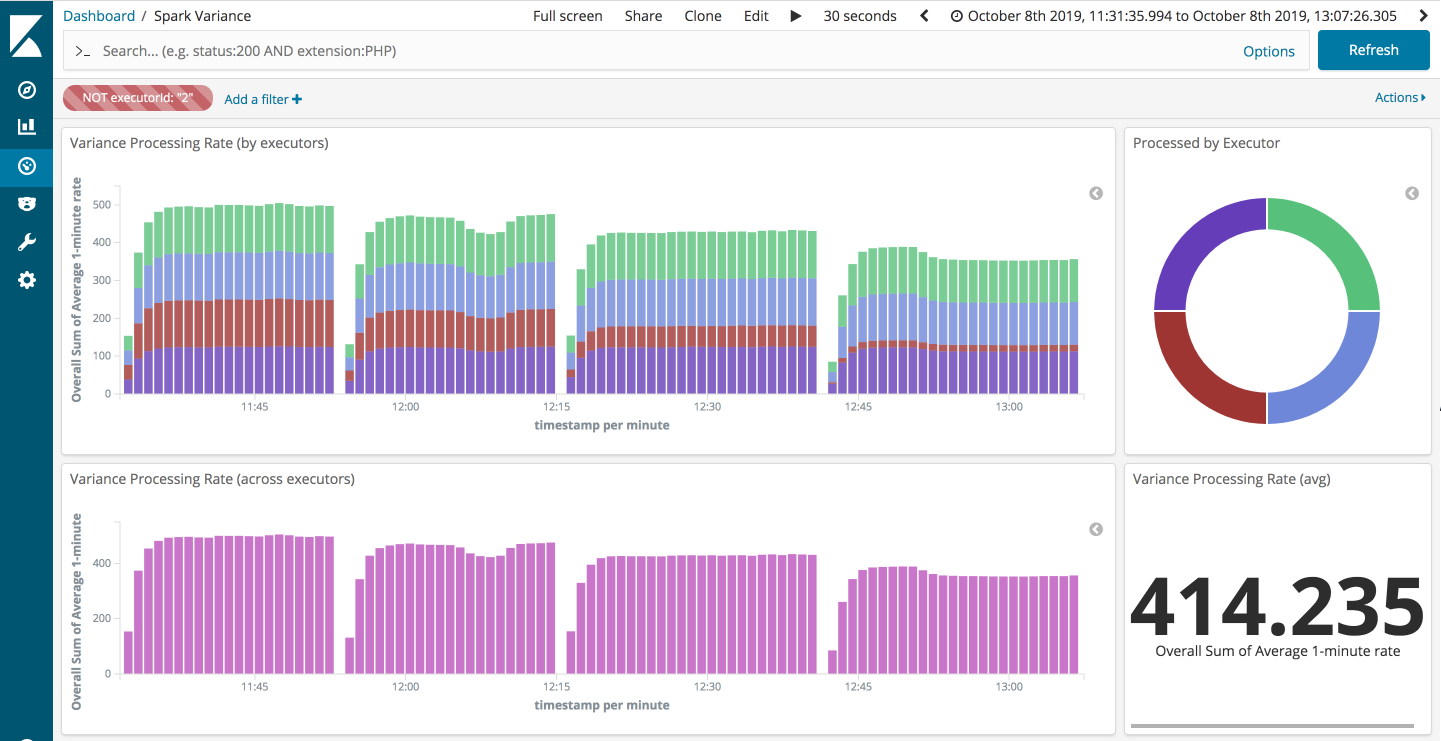
As you can see Continuous Processing seems to be pretty effective. However, the performance does drop off a little on the constant straggler scenario. This is more clearly seen if we filter out the straggler task, see below:
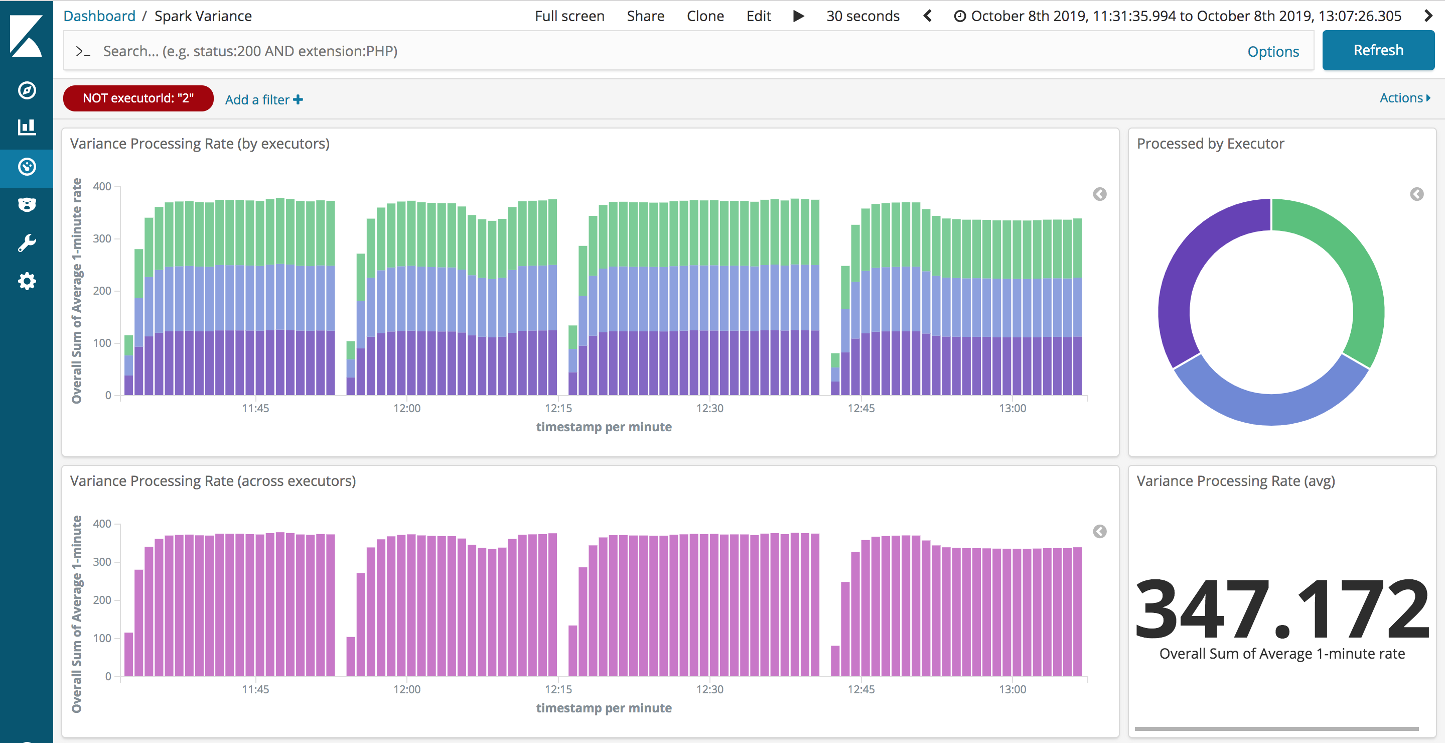
If you want to run these scenarios checkout the code in github.
Not bad at all
So overall, Spark has held up well in the face of our backpressure onslaught. Albeit with a little inside information. But requiring users to understand the basic characteristics of the platform they are using hardly seems unreasonable, especially when we are talking about distributed data processing systems.
Perhaps, worthy of note is the Spark micro-batch design, which is elegantly simple and yet very effective; even in the presence of our most gnarly backpressure scenarios. However, the nature of our non-distributed smackdown setup does give Spark a free-pass with respect to the redistribution of straggler partitions6.
We also have to acknowledge the performance hit when using DStreams with over-partitioning and that the experimental Continuous Processing mode took a hit on the constant straggler scenario. But other than that, Spark has matched Storm punch for punch.
We will compare the final figures when we round up this series at the end. Next up is Flink …
-
Discretized Streams: Fault-Tolerant Streaming Computation at Scale. ↩
-
It is worth noting that it is a right pain to do this with Spark, compared to Storm. ↩
-
As with any tuning, your mileage may vary. The redistribution of the data partitions does incur additional network I/O. This is something that is a definite weakness of my laptop-based test - as Spark gets away scot free on this front. ↩
-
See the first article in this series for a breakdown of the backpressure scenarios. ↩
-
The eagle-eyed will notice the suming of averages, for the average rate figure on the right of the dashboard, which is clearly mathmatically invalid. However, it provides us with an adequate approximate rate given the constraints of the available metrics collection. ↩
-
This is clearly a fair criticism of the existing smackdown setup and something that would be nice to rectify if I can carve out enough time at some point in the future. One other criticism could be the aggressive use of spark.locality.wait=0 in our configuration, which again might prove less effective in a distributed setting. ↩
Tags: Performance Spark Smackdown Big-data Data-Engineering
comments powered by Disqus